Rt的逆矩阵
\[ \left[ \begin{matrix} R & T \\ 0 & 1 \end{matrix} \right] \left[ \begin{matrix} R^T & -R^TT \\ 0 & 1 \end{matrix} \right] = I \]
\[ \left[ \begin{matrix} R & T \\ 0 & 1 \end{matrix} \right] \left[ \begin{matrix} R^T & -R^TT \\ 0 & 1 \end{matrix} \right] = I \]
x轴向左,y轴向上,z轴向外,显然这是一个左手坐标系
x轴向左,y轴朝下,z轴朝里,是一个左手坐标系
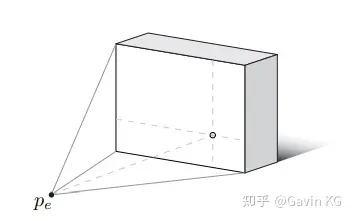
离轴渲染是指观察者在视锥体上的投影位置不位于近平面的中心点,此时投影矩阵不能假设近平面的左边界与右边界互为相反数,同样地不能假设近平面的上边界和下边界互为相反数,即
\[
r \neq l \\
t \neq b
\] 
要使用render.py实现对于3D
gaussian的离轴渲染,首先要从camera.json文件中选取一个合适的正对目标物体的机位。camera.json中的相机位姿与render.py中的坐标系需要转换:
\[
R=R_{json} \\
T=-R_{json}^TT_{json}
\]
然后确定以选出的[R|T]作为相机坐标系,确定离轴渲染的不动点p,一般设置为[0, 0, r],即位于相机坐标系中心轴上距离相机坐标系原点深度为r距离的点。
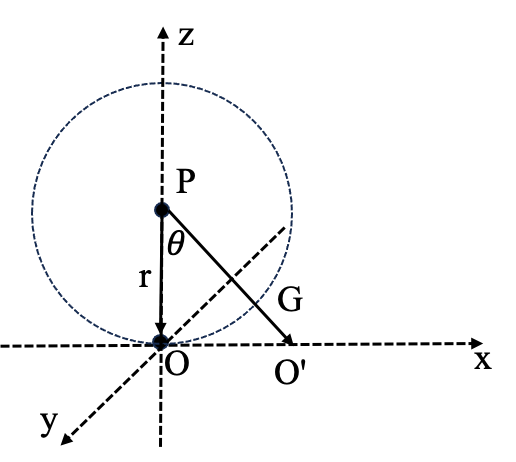
如图所示,以右手坐标系为例,点O为中心相机所在位置,O'为离轴渲染相机所在位置,新相机的旋转矩阵与中心相机一样,所以关键是确认位移\(\vec{OO'}\)
根据几何关系,\(\vec{PG'}\)可以通过\(\vec{PO}\)绕y轴\(\theta\)得到 \[ \vec{PG'}=\vec{PO}R_y(\theta) \] 如何从\(\vec{PG}\)得到\(\vec{PO'}\)呢?它们只有模长有差别,PG与OP等长,而PO‘的长度可以通过\(\theta\)角和PO确定,于是我们可以求得向量\(\vec{PO'}\) \[ ||\vec{PO'}||=||\vec{PO}||/ cos(\theta) \\ \vec{PO'} = \vec{PG'}/cos(\theta) \] 于是我们可以得到相机坐标系下的位移\(\vec{OO'}\) \[ \vec{OO'}=\vec{OP}+\vec{PO'} \\ =(P-O)+(P-O)R_y(\theta)/cos(\theta) \] 从而,我们可以得到其在相机坐标系下位姿 \[ Rt'=[I|\vec{OO'}]Rt \] 上面为右手坐标系,假如是左手坐标系就 \[ Rt'=Rt[\frac{I}{\vec{OO'}}] \]
在《3D Gaussian Splatting for Real-Time Radiance Field Rendering》中,作者通过神经网络来学习3元高斯函数的协方差,并将其协方差定义为缩放矩阵和旋转矩阵两部份。
mac安装XQuartz
1 | brew install --cask xquartz |
登陆远程服务器,确保ForwardAgent、ForwardX11、ForwardX11Trusted设置为yes
1 | vim /etc/ssh/ssh_config |
1 | Host remote_server |
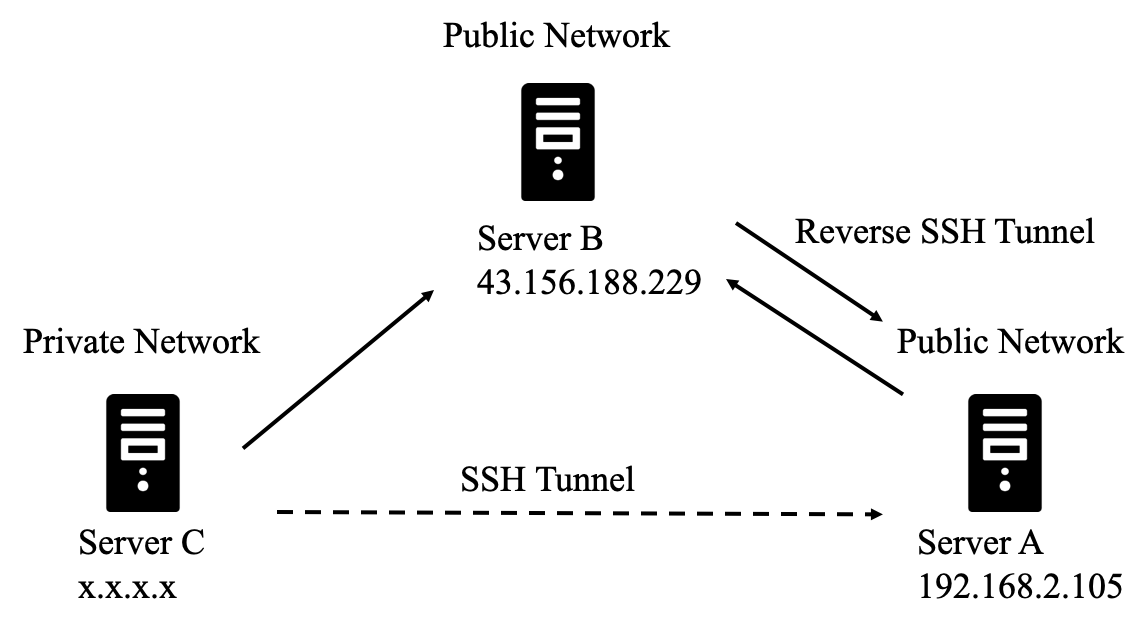
SSH 反向隧道(Reverse SSH Tunneling)是一种在防火墙或 NAT(网络地址转换)限制下实现远程访问的技术。通过建立反向隧道,可以让外部计算机访问位于私有网络中的计算机,而无需在防火墙上打开端口,从而实现内网穿透。这也是最简单的一种内网穿透方式。
“The sculpture is already complete within the marble block, before I start my work. It is already there. I just have to chisel away the superfluous material.” I'd heard Michelangelo's famous quote before. - Michelangelo

从高斯分布中采样一个噪声\(z \sim \mathcal{N}(\mathbf{\mu}, \mathbf{\Sigma})\),我们希望它输入到一个网络\(G\)之后可以输出图像x,大量的{x}可以组成一个分布,我们希望分布{x}可以与真实图像分布相近。对于文生图任务而言,只是在这个基础上加了一个condition,其本质过程和普通的生成式任务没有差别。

训练Network得到最优网络参数\(\theta\)的过程可以看作是最大似然估计:

首先,训练数据采样自真实数据,\(x^i\sim P_{data}(x)\),我们在训练过程中希望监督信息是\(x^i\)时,网络生成结果输出\(x^i\)的概率越大越好,此时网络参数最优即: \[ \theta ^{*}=arg \max_{\theta}\prod_{i=1}^mP_{\theta}(x^i) \]
为什么最大似然估计的结果就是我们想要的结果呢?此时的\(P_{\theta^*}(x)\)与\(P_{data}(x)\)相近吗?答案是肯定的,最大似然等同于最小KL散度。

概率论拾遗:假设对随机变量\(\xi\),存量两个概率分布P,Q。如果\(\xi\)为离散随机变量,定义从P到Q的KL散度为: \[ KL(P||Q)=\sum_iP(i)ln\frac{P(i)}{Q(i)} \] 如果\(\xi\)为连续随机变量,则定义P到Q的KL散度为: \[ KL(P||Q)=\int_{-\infty}^{\infty}p(x)ln\frac{p(x)}{q(x)}dx \]

对于生成模型的网络输出为x的概率,即似然估计可以写成 \[ P_{\theta}(x)=\int_z P(z)P_\theta(x|z)dz \] 其中\(P(z)\)是生成噪声\(z\)的概率,\(P_{\theta}(x|z)\)是将采样得到的噪声\(z\)输入到网络后得到结果x的概率。为什么还要积分呢?这是由于两种不同的噪声可能都可以产生结果x,即可能存在\(x=G(z_1)=G(z_2)\),所以需要考虑所有的\(z\)的可能性。那么现在如何定义\(P_\theta(x|z)\)呢?有种直观的定义是二值离散定义: \[ P_{\theta}(x|z)=\begin{cases} 1, G(z) =x \\ 0, G(z) \neq x \end{cases} \] 但这种定义太严格了,几乎很难出现两张图完全相同的情况即\(G(z)==x\),所以需要对这个概率做一些松弛。实际上按照高斯距离来衡量网络输出的图像与真值图像之间的差异,并作为网络的条件概率。 \[ P_{\theta}(x|z)\propto e^{-||G(z)-x||_2} \] 然而, 事实上直接最大化\(P_{\theta}(x)\)是很难的,实际上我们是最大化它的下界: \[ logP_{\theta}(x)=\int_zq(z|x)logP_{\theta}(x)dz \] 这里的等式对于任意分布\(q(z|x)\)都是成立的,因为\(\int_zq(z|x)logdz\)其实和\(P_{\theta}(x)\)相互独立。接下来可以得到 \[ logP_{\theta}(x)\geq \int_zq(z|x)log(\frac{P_{\theta}(z, x)}{q(z|x)})dz \\ =E_{q(z|x)}[log(\frac{P_{\theta}(x, z)}{q(z|x)})] \] 其中\(q(z|x)\)是指给定干净图像x的情况下输出随机噪声z的概率,从功能上来说它就是VAE中的Encoder。对DDPM来说是一样的,最大化似然函数等价于最大化KL散度的下界。 \[ logP_{\theta}(x_0) \rightarrow E_{q(x_1:x_t|x_0)}[log(\frac{P(x_0:x_T)}{q(x_1:x_T|x_0)})] \]

DDPM的前向和逆向过程可以看作是马尔可夫过程,逆向过程相当于求一个概率分布,为什么实际U-net的输出是一个噪音呢?这是重参化的结果。 \[ p(x_{t-1}|x_t) \] 根据贝叶斯公式,上式可以写为 \[ p(x_{t-1}|x_t)=\frac{p(x_t|x_{t-1})p(x_{t-1})}{p(x_t)} \] 如果给定\(x_0\)则上式可以表示为 \[ p(x_{t-1}|x_t, x_0) = \frac{p(x_t|x_{t-1}, x_0)p(x_{t-1}|x_0)}{p(x_t|x_0)} \]
\[ x_t = \sqrt{\alpha_t}x_{t-1}+\sqrt{\beta_t}\epsilon_t \]
其中\(\epsilon_t \sim \mathcal{N}(0, 1)\),所以\(\sqrt{\beta_t}\epsilon_t \sim \mathcal{N}(0, \beta_t)\),所以\(\beta_t\)的本质是增噪过程的噪声方差,由于\(\alpha_t=1-\beta_t\),所以增噪过程中仅有\(\beta\)这一个人工设置的参数。由于\(x_{t-1}\)为一个给定值,所以 \[ p(x_t|x_{t-1}) \sim \mathcal{N}(\sqrt{\alpha_t}x_{t-1}, \beta_t) \] 可以根据递推公式\(x_t = \sqrt{\alpha_t}x_{t-1}+\sqrt{\beta_t}\epsilon_t\)得到通项公式 \[ x_t=\sqrt{\bar\alpha_t}x_0+\sqrt{1-\bar\alpha_t}\epsilon \] 由于\(\epsilon \sim \mathcal{N}(0, 1)\),所以有\(x_t \sim \mathcal{N}(\sqrt{\bar{\alpha_t}}x_0, 1-\bar{\alpha_t})\),即在给定\(x_0\)的情况下\(x_t\)服从高斯分布 \[ p(x_t|x_0)\sim \mathcal{N}(\sqrt{\bar{\alpha_t}}x_0, 1-\bar{\alpha_t}) \] 我们此时再来看公式(12),其中 \(p(x_t|x_{t-1}, x_0)\)由于是个马尔可夫过程所以\(p(x_t|x_{t-1}, x_0)=p(x_t|x_{t-1})\),而\(p(x_t|x_{t-1}) \sim \mathcal{N}(\sqrt{\alpha_t}x_{t-1}, \beta_t)\),其中\(p(x_t|x_0)\sim \mathcal{N}(\sqrt{\bar{\alpha_t}}x_0, 1-\bar{\alpha_t})\),同样的\(p(x_{t-1}|x_0)\sim \mathcal{N}(\sqrt{\bar{\alpha}_{t-1}}x_0, 1-\bar{\alpha}_{t-1})\)。所以有 \[ p(x_{t-1}|x_t, x_0) \sim \frac{\mathcal{N}(x_t;\sqrt{\alpha_t}x_{t-1}, \beta_t)\mathcal{N}(x_{t-1};\sqrt{\bar{\alpha}_{t-1}}x_0, 1-\bar{\alpha}_{t-1})}{\mathcal{N}(x_t;\sqrt{\bar{\alpha_t}}x_0, 1-\bar{\alpha}_t)} \] 这里省去冗杂的推导过程,可以得到此时\(p(x_{t-1}|x_t, x_0)\)依然服从一个高斯分布\(\mathcal{N}(\mu_q(x_t, x_0), \sum_q(t))\)

即 \[ q(x_{t-1}|x_t, x_0)\sim \mathcal{N}(\mu(x_0, x_t), \sum(t)) \]
符号标记:\(\alpha_t=1-\beta_t,\bar\alpha_t=\Pi_{s=1}^t\alpha_s\) 其中\(\beta_t\)为增加的噪声的方差; \(\mathcal{N}(x; 0, 1)\)表示随机变量\(x\)服从高斯分布\(\mathcal{N}(0, 1)\)
去噪过程我们是不知道\(x_0\)的,所以对于式(18)而言,未知的有\(\mu(x_0, x_t)\),而为了求\(\mu(x_0, x_t)\)我们需要预估一个\(\hat{x}_0\),需要注意的是这里的\(\hat{x}_0\)并非我们最终的标签\(x_0\)。为了求\(\hat{x}_0\),我们要利用公式 \[ x_t=\sqrt{\bar\alpha_t}x_0+\sqrt{1-\bar\alpha_t}\epsilon_t \] 由于\(x_t\)和\(\bar{\alpha}_t\)已知,所以我们可以通过估计\(\epsilon_t\)来得到预估的\(\hat{x_0}\),这也是为什么U-net的输出为噪声\(\epsilon_{\theta}(x_t, t)\)。这样我们就可以求得式(18)中的均值\(\mu(\hat{x_0}, x_t)\): \[ x_{t-1} \sim \mathcal{N}(\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha_t}}\epsilon_{\theta}(x_t, t)}), \sum(t)) \] 由于我们知道了给定\(x_t\)时,\(x_{t-1}\)的分布,我们就可以采样一个\(x_{t-1}\)出来,如何进行采样呢?方法是重参化,我们先采样一个高斯噪声\(z\sim \mathcal{N}(0, 1)\),再让它乘以我们已知的方差\(\sum(t)\)再加上我们已知的均值,即可采样得到一个\(x_{t-1}\) \[ x_{t-1} =\frac{1}{\sqrt{\alpha_t}}(x_t-\frac{1-\alpha_t}{\sqrt{1-\bar{\alpha_t}}\epsilon_{\theta}(x_t, t)})+\sqrt\sum(t)z \]
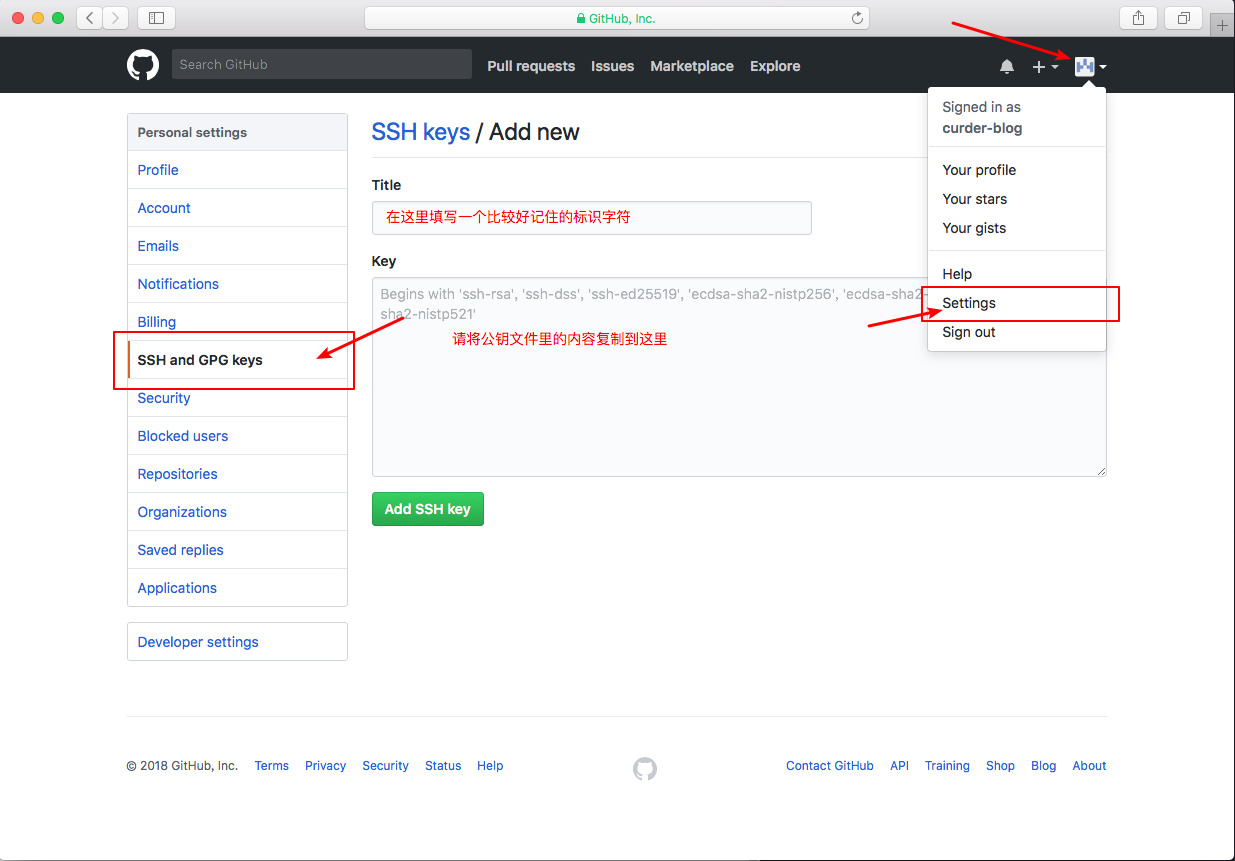
git每次pull和push都需要输入用户名和密码十分的麻烦和浪费时间,好在可以利用ssh密钥来进行git免密登录。